

What are the benefits of intelligent document processing?
IDP offers a range of benefits for businesses. The following are some of the key advantages.
Scalability
Manual document processing can result in human errors, reducing the efficiency of your business. It also introduces limits on how many documents you can process at a time. With IDP solutions, you can accurately scan documents at scale. ML/AI solutions process documents without mistakes. You can manage heavy operational demands with improved accuracy and efficiency.
Cost-efficiency
Automation of document processing and analysis reduces overhead costs. You can automate any repetitive tasks central to your operations and overcome bottlenecks, eliminating costs that arise from manual data entry and processing. You can leverage IDP to boost productivity and streamline workflows across your business operations.
Customer satisfaction
With IDP, you can handle customer documents faster. You can use IDP to automate tasks such as customer onboarding, bookings, and payments that involve documentation. Chatbots can use data from customer documents to respond to customer queries in a more personalized manner. Providing answers and services to customers more quickly enhances customer relationships.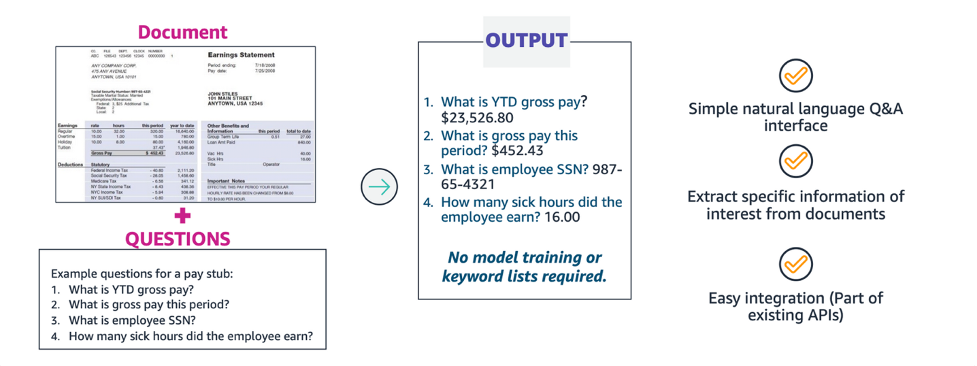
What are the technologies used in intelligent document processing?
IDP uses a range of technologies to process different kinds of documents.
Optical character recognition
Optical character recognition (OCR) converts an image of text into a machine-readable text format. You can use OCR to scan paper documents and convert them into images with searchable text data. OCR is vital to document processing because it converts paper forms, receipts, invoices, contracts, legal documents, and more into digitized documents.
There are several types of OCR, each of which has different applications:
- Simple OCR software uses matching algorithms to compare text images to text and font image pattern templates
- Intelligent character recognition (ICR) software uses ML software to process different image attributes, like curves and lines, to process text
- Intelligent word recognition uses principles similar to ICR but focuses on processing entire words instead of working on individual characters
- Optical mark recognition uses a matching algorithm to identify text systems, logos, and watermarks
Natural language processing
NLP is an ML technology that enables computers to analyze, interpret, and understand human language. NLP software processes text and voice data to analyze the sentiment, content, or intent. NLP uses a range of technologies—including ML, computational linguistics, and deep learning models—to process human language. The following are some of these technologies:
- Computational linguistics involves semantic and syntactic analysis to create frameworks that capture the essence of human language
- ML technology enables NLP models to improve their understanding of metaphors, sentence structure changes, grammar, colloquialisms, sarcasm, and other elements of human speech
- Deep learning neural networks enable computers to recognize, classify, and identify complex patterns in sample data
NLP is especially useful when working with unstructured documents and unstructured data, like live recordings or human speech.
Robotic process automation
Robotic process automation (RPA) is a form of technology that facilitates the building and deployment of software that automates human actions. You can automate business workflows with RPA software. For example, a user can record how they process a document. The RPA software then repeats the same steps, eliminating the need for manual document processing work. You can use RPA to automate any process, from data extraction to data capture and more.
How does intelligent document processing work?
IDP can interpret, classify, and extract data from a variety of document types, ranging from structured data to unstructured texts such as emails or reports. The following is an overview of the process.
Document classification
The first step in IDP is capturing and classifying documents. This involves importing both paper and digital documents into the system. Document processing tools use AI to recognize and categorize different types of scanned documents, such as invoices, purchase orders, or legal contracts. This classification is crucial for determining the subsequent processing steps for each document type.
Data extraction
After classification, the system extracts relevant data from the documents. Using OCR and NLP, IDP systems accurately identify specific information such as dates, amounts, or names.
After extraction, the system also performs data validation to ensure accuracy. For instance, the system might cross-reference extracted data with existing databases or use predefined rules to check for errors.
Data processing
After validation, the extracted data is processed according to its purpose. For instance, invoice data might be routed for payment processing, and contract details could be sent to a legal platform. The IDP system integrates with other business systems, such as ERP and CRM, for seamless data flow and automating actions based on the processed data.
Continuous learning
A key feature of IDP systems is their ability to learn and improve over time. By using ML algorithms, the systems learn from previous errors and adapt to changes in document formats to enhance accuracy. The continuous learning process ensures that the system remains effective even as business needs and document types evolve.
Reporting and analytics
IDP systems can track metrics such as processing time, error rates, and throughput volumes. They can be further processed by business analytics to derive insights that help identify bottlenecks, improve workflows, and make data-driven decisions for overall efficiency.
How can AWS help with intelligent document processing?
Amazon Web Services (AWS) offers two services to support your IDP requirements.
Amazon Textract makes it easy to automatically extract handwriting, layout elements, printed text, and data from any document. Amazon Textract uses ML to read, process, and understand any type of document without the need for manual interaction. With Amazon Textract, you can:
- Extract vital information from business documents with a high degree of accuracy
- Scale your document processing pipeline so that you have the flexibility that you need to adapt to market demands
- Automate data processing in a secure environment that meets compliance standards
Amazon Comprehend is an NLP service that uses ML to uncover valuable insights and connections in text. It’s a fully managed and continuously trained service, so you don’t have to manage the scaling of resources, maintenance of code, or maintenance of the training data. With Amazon Comprehend, you can:
- Discover valuable insights from text in any form of document
- Simplify the document processing pipeline by extracting sentiment, text, phrases, or topics from documents
- Identify and redact personally identifiable information (PII) from private documents
Learn how to build an end-to-end IDP solution with Amazon Textract and Amazon Comprehend.
Get started with intelligent document processing on AWS by signing up for an account today.



